Media Summary: In this episode of PaperX, we dive into " Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... Try Voice Writer - speak your thoughts and let AI handle the grammar:
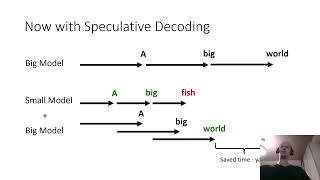
Speculative Speculative Decoding How To - Detailed Analysis & Overview
In this episode of PaperX, we dive into " Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... Try Voice Writer - speak your thoughts and let AI handle the grammar: Lex Fridman Podcast full episode: Thank you for listening ❤ Check out our ... arxiv - Become AI Researcher & Train LLM From Scratch ... In this AI Research Roundup episode, Alex discusses the paper: 'Domino: Decoupling Causal Modeling from Autoregressive ...
One Click Templates Repo (free): Advanced Inference Repo (Paid Lifetime ... In this video, I will show you how to properly configure