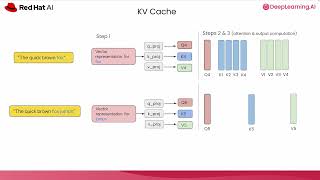
Media Summary: Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... High latency is the primary bottleneck for delivering responsive, user-facing large language model ( A walkthrough of some of the options developers are faced with when building applications that leverage
Faster Llms Accelerate Inference With - Detailed Analysis & Overview
Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... High latency is the primary bottleneck for delivering responsive, user-facing large language model ( A walkthrough of some of the options developers are faced with when building applications that leverage In this deep dive, we'll explain how every modern Large Language Model, from LLaMA to GPT-4, uses the KV Cache to make ... Discover a simple method to calculate GPU memory requirements for large language models like Llama 70B. Learn how the ... Set Block Decoding (SBD), introduced by researchers at FAIR/Meta, is a breakthrough in
Download the AI model guide to learn more → Learn more about the technology → Welcome to machine learning & AI monthly for June 2025. This is the video version of the newsletter I write every month which ...