Media Summary: Zyphra has developed a novel sequence mixing layer called This video is about TURBOQUANT, an efficient Try Voice Writer - speak your thoughts and let AI handle the grammar: Residual
Online Vector Quantized Attention Press - Detailed Analysis & Overview
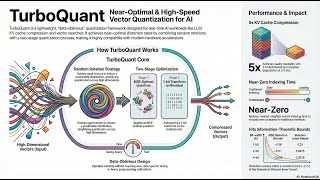
Zyphra has developed a novel sequence mixing layer called This video is about TURBOQUANT, an efficient Try Voice Writer - speak your thoughts and let AI handle the grammar: Residual Is your AI too slow or using too much memory? TurboQuant is a new way to shrink AI data so it's lightning-fast but still perfectly ... Title: Hierarchical Imitation Learning with [CVPR 2023 Highlight presentation] Towards Accurate Image Coding: Improved Autoregressive Image Generation with Dynamic ...
In this video I will introduce and explain









![[CVPR 2023 Highlight presentation] Autoregressive Image Generation with Dynamic Vector Quantization](https://i.ytimg.com/vi/ir60YW9JCjU/mqdefault.jpg)

