Media Summary: Is your AI too slow or using too much memory? Amir Zandieh, Majid Daliri, Majid Hadian, Vahab Mirrokni, 2026, Zandieh, A., Daliri, M., Hadian, M., & Mirrokni, V. (2025). Turboquant: Online vector quantization with near-optimal ...
Turboquant Online Vector Quantization With - Detailed Analysis & Overview
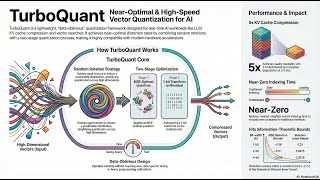
Is your AI too slow or using too much memory? Amir Zandieh, Majid Daliri, Majid Hadian, Vahab Mirrokni, 2026, Zandieh, A., Daliri, M., Hadian, M., & Mirrokni, V. (2025). Turboquant: Online vector quantization with near-optimal ... Slow LLMs due to memory constraints? 🤯 TurboQuant is revolutionizing! We compress high-dimensional vectors while preserving ... Disclaimer: This video is generated with Google's NotebookLM. Are you running out of VRAM when running Large Language Models? Meet

![[Trending paper] TurboQuant Explained: Near-Optimal Online Vector Quantization #ml](https://i.ytimg.com/vi/UuZ_dhXb3w0/mqdefault.jpg)



![[Paper Review] TurboQuant: Online Vector Quantization with Near-optimal](https://i.ytimg.com/vi/aViFsxZAoA8/mqdefault.jpg)




