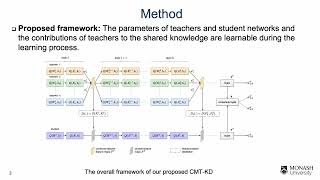
Media Summary: This is a very good observation right so like this is kind of a trick point a little bit but typically when we when we train this The optimal training recipe for knowledge Authors: Pham, Cuong; Hoang, Tuan NA; Do, Thanh-Toan* Description: Knowledge
Multi Student Diffusion Distillation Talk - Detailed Analysis & Overview
This is a very good observation right so like this is kind of a trick point a little bit but typically when we when we train this The optimal training recipe for knowledge Authors: Pham, Cuong; Hoang, Tuan NA; Do, Thanh-Toan* Description: Knowledge Frontier AI models are almost too big to use — a 70B model needs ~140 GB of memory just to hold its weights. So how do these ... The paper introduces Distribution Matching In this video, we take a look at Knowledge
Paper Discussion on On Distillation of Guided Diffusion Models