Media Summary: Authors: Pham, Cuong; Hoang, Tuan NA; Do, Thanh-Toan* Description: Authors: Qiushan Guo, Xinjiang Wang, Yichao Wu, Zhipeng Yu, Ding Liang, Xiaolin Hu, Ping Luo Description: This work presents ... How can we create smaller, faster language models that retain the power of their massive "
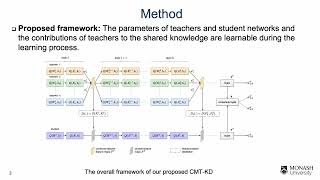
Collaborative Multi Teacher Knowledge Distillation - Detailed Analysis & Overview
Authors: Pham, Cuong; Hoang, Tuan NA; Do, Thanh-Toan* Description: Authors: Qiushan Guo, Xinjiang Wang, Yichao Wu, Zhipeng Yu, Ding Liang, Xiaolin Hu, Ping Luo Description: This work presents ... How can we create smaller, faster language models that retain the power of their massive " Authors: Jacob, Geethu M*; agarwal, vishal; Stenger, Bjorn Description: In this AI Research Roundup episode, Alex discusses the paper: ' Authors: Kai Wang, Yu Liu, Qian Ma, Quan Z. Sheng.
Question Answering and Summarisation (W1.4) [fp] MTMS: In this AI Research Roundup episode, Alex discusses the paper: 'Heterogeneous Agent




![[MSc Thesis] Multi-Teacher Knowledge Distillation for Accented English Speech Recognition](https://i.ytimg.com/vi/n5lFmgq_Fy0/mqdefault.jpg)




![SIGIR 2024 W1.4 [fp] MTMS: Multi-teacher Multi-stage Knowledge Distillation](https://i.ytimg.com/vi/apIbF4LNt18/mqdefault.jpg)

