Media Summary: This is the supplementary video for the ICRA 25 publication on finetuning of LeRobot Research Presentation Presented by Cheng Chi in April 2024 This week: This is the first session with Roger leading a discussion about
Fdpp Fine Tune Diffusion Policy - Detailed Analysis & Overview
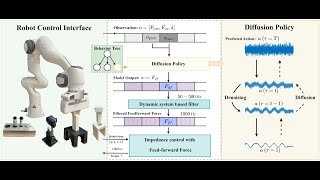
This is the supplementary video for the ICRA 25 publication on finetuning of LeRobot Research Presentation Presented by Cheng Chi in April 2024 This week: This is the first session with Roger leading a discussion about In this episode of *Robraintics*, we discuss why What's better than an image generation model? One that can generate YOUR specific images! GUIDE SHOWN IN VIDEO: ... Assembly is a crucial skill for robots in both modern manufacturing and service robotics. However, mastering transferable insertion ...
Princeton University - Nov 3, 2023 Speaker: Russ Tedrake (MIT) Talk title: Dexterous Manipulation with Direct Preference Optimization (DPO) is a method used for training Large Language Models (LLMs). DPO is a direct way to train ...










![[research] Diffusion Policy: Visuomotor Policy Learning via Action Diffusion](https://i.ytimg.com/vi/CtJDROYBmSs/mqdefault.jpg)
