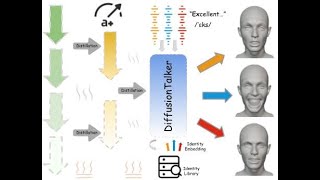
Media Summary: ACM Transactions on Graphics (Proc. SIGGRAPH 2017) ... [CVPR2023] DiffTalk: Crafting Diffusion Models for Generalized Audio-Driven Portraits Animation blacksstopkillingblackschallenge_360 Speech-
Facetalk Audio Driven Motion Diffusion - Detailed Analysis & Overview
ACM Transactions on Graphics (Proc. SIGGRAPH 2017) ... [CVPR2023] DiffTalk: Crafting Diffusion Models for Generalized Audio-Driven Portraits Animation blacksstopkillingblackschallenge_360 Speech- Paper abstract: Conventional methods for human In this video, we present our paper published at CVPR 2023, CodeTalker: Speech- Voice2Face generates facial and tongue animations directly from recorded speech using machine learning. Read our research ...



![[CVPR2023] DiffTalk: Crafting Diffusion Models for Generalized Audio-Driven Portraits Animation](https://i.ytimg.com/vi/tup5kbsOJXc/mqdefault.jpg)





![[CVPR 2023] CodeTalker: Speech-Driven 3D Facial Animation with Discrete Motion Prior](https://i.ytimg.com/vi/J2RngmuYrG4/mqdefault.jpg)