Media Summary: If you have any copyright issues on video, please send us an email at khawar512.com. In this video, we present our paper published at CVPR 2023, CodeTalker: We reduce the steps of the diffusion model for faster inference by knowledge distillation. Based on the model with fewer steps, ...
Diffspeaker Speech Driven 3d Facial - Detailed Analysis & Overview
If you have any copyright issues on video, please send us an email at khawar512.com. In this video, we present our paper published at CVPR 2023, CodeTalker: We reduce the steps of the diffusion model for faster inference by knowledge distillation. Based on the model with fewer steps, ... DEEPTalk: Dynamic Emotion Embedding for Probabilistic Speech-Driven 3D Face Animation This is an early version of speech2face model using videos captured in Tencent's Siren project as training data.





![[CVPR 2023] CodeTalker: Speech-Driven 3D Facial Animation with Discrete Motion Prior](https://i.ytimg.com/vi/J2RngmuYrG4/mqdefault.jpg)

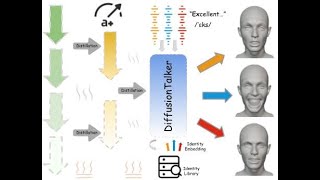
![[SIGGRAPH 2024] DiffPoseTalk: Speech-Driven Stylistic 3D Facial Animation and Head Pose Generation](https://i.ytimg.com/vi/l4BGcyawAh8/mqdefault.jpg)



