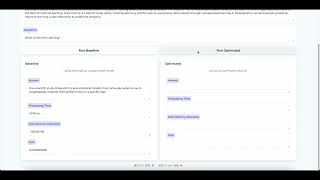
Media Summary: Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... High latency is the primary bottleneck for delivering responsive, user-facing large language model (LLM) applications. How can ... Presented by John Kehrli, Senior Director, Product Management, Qualcomm. The Cloud AI 100 accelerator offers leadership class ...
Accelerating Performance Inference Over Closed - Detailed Analysis & Overview
Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... High latency is the primary bottleneck for delivering responsive, user-facing large language model (LLM) applications. How can ... Presented by John Kehrli, Senior Director, Product Management, Qualcomm. The Cloud AI 100 accelerator offers leadership class ... This episode dives into the real cost center of AI— Speaker: Mohamed Ibrahim, University of Toronto Field Programmable Gate Arrays (FPGAs) are programmable devices that can ... In this episode, we sit down with Solution Architect Robert Alvarez to discuss the technology behind Pure Key-Value Accelerator ...
Discover how Premio and MemryX are redefining edge AI