Media Summary: Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... The open AI ecosystem is thriving—powered by a new wave of high-performance Faradawn Yang delivers a three-part hands-on workshop covering
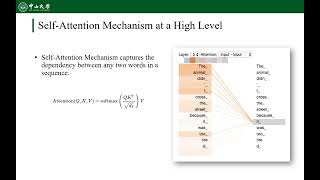
Accelerate Transformer Inference On Gpu - Detailed Analysis & Overview
Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... The open AI ecosystem is thriving—powered by a new wave of high-performance Faradawn Yang delivers a three-part hands-on workshop covering Watch Lysandre Debut & Sylvain Gugger from Hugging Face present their PyTorch Conference 2022 Talk "Run Very Large ... Deploying AI models at scale demands high-performance Don't miss out! Join us at our upcoming event: KubeCon + CloudNativeCon Europe 2021 Virtual from May 4–7, 2021. Learn more ...
Jiangsu Du, Jiazhi Jiang, Yang You, Dan Huang, Yutong Lu Session 11: Machine Learning.