Media Summary: Try Voice Writer - speak your thoughts and let AI handle the grammar: Four techniques to optimize the speed ... This video introduces a novel, straightforward yet effective Paper link: Presented in ACL 2022 Structured
Wanda Network Pruning Prune Llms - Detailed Analysis & Overview
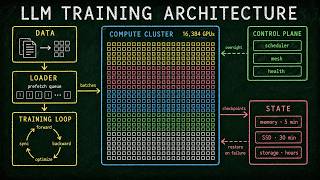
Try Voice Writer - speak your thoughts and let AI handle the grammar: Four techniques to optimize the speed ... This video introduces a novel, straightforward yet effective Paper link: Presented in ACL 2022 Structured Research shows that 58% of data scientists are not optimizing their deep learning models for production, despite the significant ... DeepSeek-V3 trained a high-quality 671B parameter MoE model for $5.6M using 2048 GPUs. Llama 3 405B used 16384 H100s ... Learning both Weights and Connections for Efficient Neural
This Tech Talk explores how to compress neural