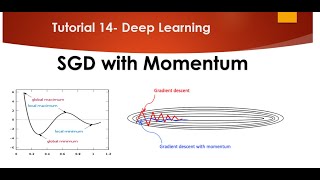
Media Summary: In this post I'll talk about simple addition to classic SGD algorithm, called momentum which almost always works better and faster ... We go through normal Gradient Descent before we finish up with Teachers for the training data in memory at once and by using
Tutorial 14 Stochastic Gradient Descent - Detailed Analysis & Overview
In this post I'll talk about simple addition to classic SGD algorithm, called momentum which almost always works better and faster ... We go through normal Gradient Descent before we finish up with Teachers for the training data in memory at once and by using Below are the various playlist created on ML,Data Science and Deep Learning. Please subscribe and support the channel. Happy ... ... Professor Suvrit Sra gives this guest lecture on ... workhorse algorithm for optimization of parameters and weights in a neural network: the