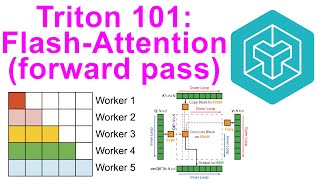
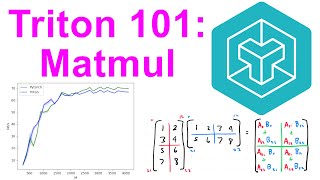
Media Summary: For more information about Stanford's online Artificial Intelligence programs visit: To learn more about ... Matrix Multiplication is the heart of every Transformer model. If it's slow, your model is slow. In this episode of Bielik Anatomy, we ...
Triton Gpu Kernels Lesson 9 - Detailed Analysis & Overview
For more information about Stanford's online Artificial Intelligence programs visit: To learn more about ... Matrix Multiplication is the heart of every Transformer model. If it's slow, your model is slow. In this episode of Bielik Anatomy, we ...