Media Summary: ASPLOS'22: The 27th International Conference on Architectural Support for Programming Languages and Operating Systems ... LinuxCon and CloudOpen North America, 2013: " ASPLOS'23: The 28th International Conference on Architectural Support for Programming Languages and Operating Systems ...
Transparent Memory Offloading Meta Niket - Detailed Analysis & Overview
ASPLOS'22: The 27th International Conference on Architectural Support for Programming Languages and Operating Systems ... LinuxCon and CloudOpen North America, 2013: " ASPLOS'23: The 28th International Conference on Architectural Support for Programming Languages and Operating Systems ... Learn more about LLM inference here → Why do LLMs crawl when traffic spikes? Legare Kerrison ... As llm serve more users and generate longer outputs, the growing In this video from the 2018 OpenFabrics Workshop, Liran Liss from Mellanox presents: NVMf Target
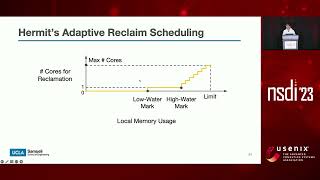
Bernie Wu's presentation at AI Field Day 6 detailed MemVerge's Hermit: Low-Latency, High-Throughput, and