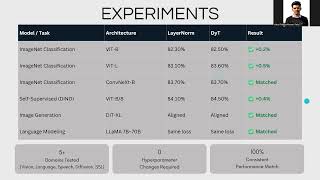
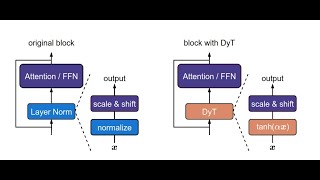
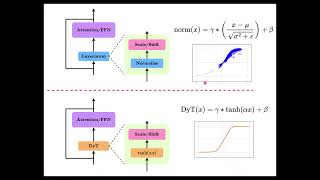
Media Summary: LayerNorm is outdated? Let's find it out together. This episode of TalkTensors dives into a groundbreaking Chapters 00:00 - 03:45 Introduction 03:45 - 16:06 Methodology 16:06 - 21:25 Results 21:25 - 39:46
Transformers Without Normalization Paper Explained - Detailed Analysis & Overview
LayerNorm is outdated? Let's find it out together. This episode of TalkTensors dives into a groundbreaking Chapters 00:00 - 03:45 Introduction 03:45 - 16:06 Methodology 16:06 - 21:25 Results 21:25 - 39:46 As a regular normal SWE, want to share several key topics to better understand