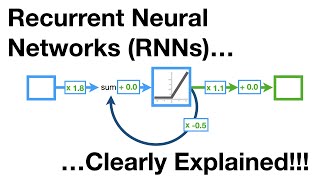
Media Summary: Learn how to make RNNs 30 times faster at small mini-batch sizes - allowing data parallel scaling to 16 times more GPUs - and ... Warp-CTC is an implementation of the #CTC algorithm for #CPUs and NVIDIA #GPUs. Researchers can directly call the C ... Phased LSTM Accelerating Recurrent Network Training for Long or Event based Sequences mid
Svail Tech Notes Accelerating Recurrent - Detailed Analysis & Overview
Learn how to make RNNs 30 times faster at small mini-batch sizes - allowing data parallel scaling to 16 times more GPUs - and ... Warp-CTC is an implementation of the #CTC algorithm for #CPUs and NVIDIA #GPUs. Researchers can directly call the C ... Phased LSTM Accelerating Recurrent Network Training for Long or Event based Sequences mid (section 3.7 and section 7) More about Baidu's efficient deep speech deployment thanks to ... In this second instalment in our Seequent Evo webinar series. Driver brings machine learning to geological modelling. When you don't always have the same amount of data, like when translating different sentences from one language to another, ...
Want to play with the technology yourself? Explore our interactive demo → Learn more about the ... If you enjoy this, check out my other content at www.michaelphi.com In this AI Research Roundup episode, Alex discusses the paper: 'Pretraining




![Accelerate Your Geological Modelling and Insights with Machine Learning in Driver [Webinar 2026]](https://i.ytimg.com/vi/AN38E0L-z-A/mqdefault.jpg)