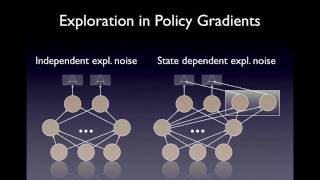
Media Summary: Reparameterized Policy Learning for Multimodal The talk gives an overview how PGPE and MultiPGPE work in contrast to standard Don't like the Sound Effect?:* *Text:* ...
Reparameterized Policy Learning For Multimodal - Detailed Analysis & Overview
Reparameterized Policy Learning for Multimodal The talk gives an overview how PGPE and MultiPGPE work in contrast to standard Don't like the Sound Effect?:* *Text:* ... Here we introduce dynamic programming, which is a cornerstone of model-based reinforcement In this video, we continue our journey into dynamic programming in reinforcement In this video, I break down DeepSeek's Group Relative