Media Summary: In this AI Research Roundup episode, Alex discusses the paper: ' LeRobot Research Presentation Presented by Cheng Chi in April 2024 This week: Diffusion Policy ... Most of us have encountered situations where someone appears to share our views or values, but is in fact only pretending to do ...
Repa Representation Alignment For Generation - Detailed Analysis & Overview
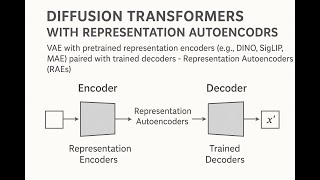
In this AI Research Roundup episode, Alex discusses the paper: ' LeRobot Research Presentation Presented by Cheng Chi in April 2024 This week: Diffusion Policy ... Most of us have encountered situations where someone appears to share our views or values, but is in fact only pretending to do ... In this AI Research Roundup episode, Alex discusses the paper: 'What matters for This video covers the Vision Transformer (ViT), Diffusion Transformer (DiT) and Multimodal Diffusion Transformer (MMDiT). This is ... Positional information is critical in transformers' understanding of sequences and their ability to generalize beyond training context ...
For more information about Stanford's online Artificial Intelligence programs visit: To learn more about ... What happens when diffusion models start learning to think in rewards, scores, and Gibbs corrections? In this episode, we dive ...








![How Rotary Position Embedding Supercharges Modern LLMs [RoPE]](https://i.ytimg.com/vi/SMBkImDWOyQ/mqdefault.jpg)


