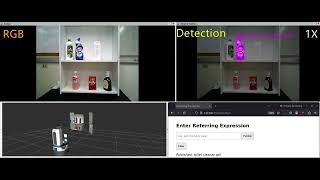
Media Summary: In this video, we show our Fetch robot using MRVG-Net. When you give the robot a command or describe an object, it quickly finds ... Title: Unlimited OCR Works (Jun 2026) Link: Date: June 2026 Summary: Baidu researchers ... In this episode of Artificial Intelligence: Papers and Concepts, we explore Molmo Point, an extension of
Real World Multimodal Reference Visual - Detailed Analysis & Overview
In this video, we show our Fetch robot using MRVG-Net. When you give the robot a command or describe an object, it quickly finds ... Title: Unlimited OCR Works (Jun 2026) Link: Date: June 2026 Summary: Baidu researchers ... In this episode of Artificial Intelligence: Papers and Concepts, we explore Molmo Point, an extension of Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... Vision-Language Models (VLMs) are transforming Artificial Intelligence by enabling machines to understand **images and natural ... In this episode we look at the architecture and training of
Try Dreamina Seedance: I accidentally made a music video using Dreamina Seedance 2.0. This video explores 64 cutting-edge computer vision papers published on May 7, 2025, highlighting six major research themes ... In the beginning of the universe, all was darkness — until the first organisms developed sight, which ushered in an explosion of ... Production agents for travel, logistics, and consumer apps demand rigorous Referential neural listeners that operate directly in 3D










![ReferIt3D:Neural Listeners for Fine-Grained 3D Object Identification in Real-World Scenes [ECCV2020]](https://i.ytimg.com/vi/yEdf24hF_sY/mqdefault.jpg)