Media Summary: Task2: Finding the optimal number of clusters for our Unlabelled data.
Prediction Using Unsupervised Ml K - Detailed Analysis & Overview
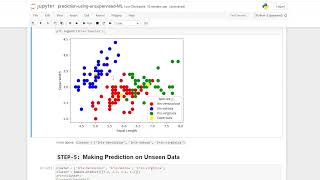
Task2: Finding the optimal number of clusters for our Unlabelled data.
Media Summary: Task2: Finding the optimal number of clusters for our Unlabelled data.
Task2: Finding the optimal number of clusters for our Unlabelled data.
This project is for the beginner level

internship2020 #griptask #GRIPNOV2020 #thesparksfoundation #datascience #kmeans #github.

I have

Task2: Finding the optimal number of clusters for our Unlabelled data.

From the given 'Iris' dataset,

From the given 'Iris' dataset,

From the given 'Iris' dataset,

K

predicting

Task 2

datascience #dataanalysis #machinelearning #kmeansclustering.

This is a python code for

code link:https://github.com/sahilhatkar/The-spark-foundation-task-2.