Media Summary: Mengdi Wang (Princeton University) Adversarial Approaches in Machine Learning. The machine learning consultancy: Join my email list to get educational and useful articles (and nothing else!) Lecture 3 of a 6-lecture series on the Foundations of Deep RL Topic:
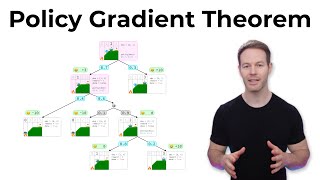
Policy Gradient Optimal Estimation Convergence - Detailed Analysis & Overview
Mengdi Wang (Princeton University) Adversarial Approaches in Machine Learning. The machine learning consultancy: Join my email list to get educational and useful articles (and nothing else!) Lecture 3 of a 6-lecture series on the Foundations of Deep RL Topic: Instructor: Andrej Karpathy (Tesla) Lecture 4B Deep RL Bootcamp Berkeley August 2017 The Machine Learning Center at Georgia Tech (ML) regularly hosts renowned professors and industry leaders on campus as ... Reinforcement Learning Course by David Silver# Lecture 7:
To learn more about enrolling in the graduate course, visit: ... Alekh Agarwal (Microsoft Research Redmond) Emerging Challenges in Deep Learning. Don't like the Sound Effect?:* *Text:* ...