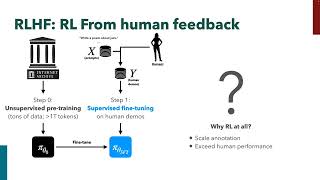
Media Summary: TU Delft Delft Center for Systems and Control (DCSC) Colloquia Series – Recording How can ChatGPT undoubtedly turned the AI industry upside-down, making AI technology mainstream. A key component behind ... In the second part of the video, I will derive from first principles the Policy Gradient
Optimization Algorithm For Feedback And - Detailed Analysis & Overview
TU Delft Delft Center for Systems and Control (DCSC) Colloquia Series – Recording How can ChatGPT undoubtedly turned the AI industry upside-down, making AI technology mainstream. A key component behind ... In the second part of the video, I will derive from first principles the Policy Gradient Generative Large Language Models, like ChatGPT and DeepSeek, are trained on massive text based datasets, like the entire ... In this video, I break down Proximal Policy The 32nd International Conference on Algorithmic Learning Theory (ALT 2021) Title: Online Boosting with Bandit
Want to play with the technology yourself? Explore our interactive demo → Learn more about the ... This video accompanies our paper “Preferential Bayesian Guest lecture in CS 285 by Eric Mitchell (Stanford)