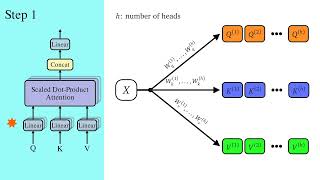
Media Summary: In this video, I will first give a recap of Scaled Dot-Product Attention, and then dive into What if your AI could look at a sentence from 4 different angles — simultaneously? That's exactly what What if one architecture tweak made Llama 3 5× faster with 99.8% of the quality? In this deep dive, we break down Grouped ...
Multi Head Attention Mha Multi - Detailed Analysis & Overview
In this video, I will first give a recap of Scaled Dot-Product Attention, and then dive into What if your AI could look at a sentence from 4 different angles — simultaneously? That's exactly what What if one architecture tweak made Llama 3 5× faster with 99.8% of the quality? In this deep dive, we break down Grouped ... Transformer implementation from scratch (in Tensorflow): ... "Thanks for watching! If you found this helpful, click here to subscribe for more: ...