Media Summary: MIST : Multi-modal Iterative Spatial-Temporal Transformer for Long-formVideo Question Answering Video presentation in 8 minutes of our CVPR 2023 paper: Creating high-quality character animation remains an intricate and cumbersome process that requires skill, training, and ...
Mist Multi Modal Iterative Spatial - Detailed Analysis & Overview
MIST : Multi-modal Iterative Spatial-Temporal Transformer for Long-formVideo Question Answering Video presentation in 8 minutes of our CVPR 2023 paper: Creating high-quality character animation remains an intricate and cumbersome process that requires skill, training, and ... Modulated Detection for End to End Multi Modal Understanding (MDETR) Learn more details about this course: To follow ... Check out to learn more. This experiment helps visualize what's happening in machine learning.
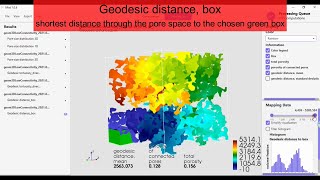
Connectivity methods based on distances computed within the pore