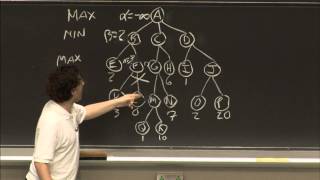Media Summary: Tutorial about how to program Google's Teaching We implement a multilayer perceptron (MLP) character-level language model. In this video we also introduce many basics of ... MIT 6.034 Artificial Intelligence, Fall 2010 View the complete course: Instructor: Mark Seifter This ...
Micro Pals Combining Machine Learning - Detailed Analysis & Overview
Tutorial about how to program Google's Teaching We implement a multilayer perceptron (MLP) character-level language model. In this video we also introduce many basics of ... MIT 6.034 Artificial Intelligence, Fall 2010 View the complete course: Instructor: Mark Seifter This ... Subscribe to our channel to get notified when we release a new video. Like the video to tell YouTube that you want more content ... A new class of small models is emerging with the ability to reliably follow instructions and call tools while running on-device under ... This video explains the fundamentals behind the Minimax algorithm and Alpha-Beta Pruning and how it can be utilized in ...
Find out more and download the code here: ... ML Performance Reading Group Session 6 recording, in which we covered Zero Bubble Pipeline Parallelism. We also cover 2 key ... MiniMax-M2 is not just a bigger model. The paper's core claim is that sparse activation, grounded agent data, and long-horizon RL ...