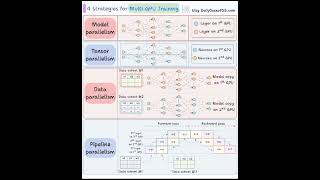
Media Summary: Welcome back! In this technical briefing designed for AI engineering managers and leads, we dive deep into the architecture and ... Training a 7B, 7-B, or even 500B parameter model on a single GPU? Impossible. In this step-by-step guide you'll learn how to ... Ever wondered how massive AI models like GPT or Llama run across dozens of GPUs at once? That's where tensor
Mastering 4d Parallelism Scale Your - Detailed Analysis & Overview
Welcome back! In this technical briefing designed for AI engineering managers and leads, we dive deep into the architecture and ... Training a 7B, 7-B, or even 500B parameter model on a single GPU? Impossible. In this step-by-step guide you'll learn how to ... Ever wondered how massive AI models like GPT or Llama run across dozens of GPUs at once? That's where tensor Large language models have led to state-of-the-art accuracies across a range of tasks. However, training these large models ... Sign up for AssemblyAI's speech API using my link ... Speaker: Nouamane Tazi (00:00:00): High Level Overview ...
For more information about Stanford's online Artificial Intelligence programs, visit: To learn more about ... Episode 83 of the Stanford MLSys Seminar Series! Training Large Language Models at We are excited to feature Nouamane Tazi, Research Engineer at Hugging Face, discussing " Unlock the genius-level engineering that makes Large Language Models (LLMs) possible. In this video, we pull back the curtain ... In this talk we present how we trained a 530B parameter language model on a DGX SuperPOD with over 3000 A100 GPUs and a ...