Media Summary: Want to learn real AI Engineering? Go here: Want to start freelancing? Let me help: ... Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your For more information about Stanford's graduate programs, visit: November 21, ...
Llm Evaluation Datasets Test Cases - Detailed Analysis & Overview
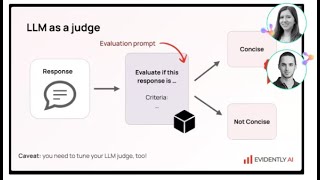
Want to learn real AI Engineering? Go here: Want to start freelancing? Let me help: ... Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your For more information about Stanford's graduate programs, visit: November 21, ... In this video, we'll explore DeepEval, a powerful framework for That new model claiming "state-of-the-art" on public benchmarks? It might have memorized the answers. Research shows ... In this video we continue the GenAI evalution series with MLflow. We expand upon the basic unit of a trace and talk about built-in ...
In this webinar, we heard firsthand about the challenges and opportunities presented by