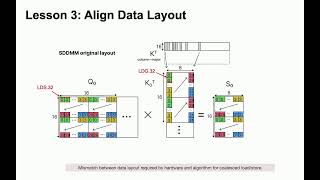
Media Summary: An illustrated, plain-English walkthrough of the SubQ-1.1-Small Technical Report from Subquadratic AI — a long-context ... Take your personal data back with Incogni! Use code WELCHLABS at the link below and get 60% off an annual plan: ... Please provide the abstract you would like me to summarize. YouTube: ...
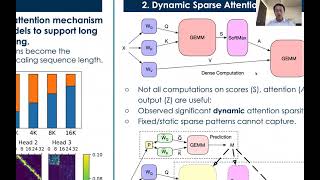
Is Sparse Attention More Interpretable - Detailed Analysis & Overview
An illustrated, plain-English walkthrough of the SubQ-1.1-Small Technical Report from Subquadratic AI — a long-context ... Take your personal data back with Incogni! Use code WELCHLABS at the link below and get 60% off an annual plan: ... Please provide the abstract you would like me to summarize. YouTube: ... This has been my favorite video so far to make! I think This is the video of the poster "Transformer Acceleration with Dynamic One of the core roadblocks to understanding the computation inside a transformer is the fact that individual neurons do not seem ...




![The Dark Matter of AI [Mechanistic Interpretability]](https://i.ytimg.com/vi/UGO_Ehywuxc/mqdefault.jpg)





![Hoagy Cunningham — Finding distributed features in LLMs with sparse autoencoders [TAIS 2024]](https://i.ytimg.com/vi/HPLIl9ZOpUQ/mqdefault.jpg)