Media Summary: Ready to become a certified watsonx Generative AI Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... Get a Free System Design PDF with 158 pages by subscribing to our weekly newsletter.: Animation ... Try Voice Writer - speak your thoughts and let AI handle the grammar: The KV
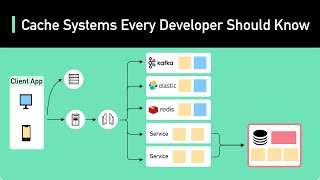
How To Cache Model Responses - Detailed Analysis & Overview
Ready to become a certified watsonx Generative AI Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... Get a Free System Design PDF with 158 pages by subscribing to our weekly newsletter.: Animation ... Try Voice Writer - speak your thoughts and let AI handle the grammar: The KV Don't leave your software engineering career to chance. Make sure you're interview-ready with Exponent's system design ... In this video, I explain how to efficiently In this deep dive, we'll explain how every modern Large Language
Gumroad Link to Assets in Video: Join the Early AI-dopters Community: Book a ... Want to master Clean Architecture? Go here: Want to unlock Modular Monoliths? Go here: ... What if you could skip redundant LLM calls — and make your AI app faster, cheaper, and smarter? In this video, ...