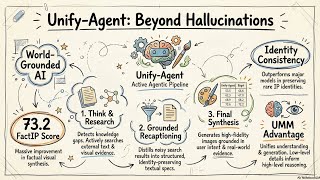
Media Summary: Today's episode dives into three very different frontiers of AI: can A technical report on Unify-Agent developed by joint researchers such as UCLA and Tencent introduces agent-based artificial ... Welcome to Frontiers - a series where we bring top researchers, engineers, designers, and leaders working at the cutting edge of ...
From Solver Grounded Multimodal Models - Detailed Analysis & Overview
Today's episode dives into three very different frontiers of AI: can A technical report on Unify-Agent developed by joint researchers such as UCLA and Tencent introduces agent-based artificial ... Welcome to Frontiers - a series where we bring top researchers, engineers, designers, and leaders working at the cutting edge of ... In this AI Research Roundup episode, Alex discusses the paper: 'Reading, Not Thinking: Understanding and Bridging the ... In this talk, Richard describes deep learning algorithms that learn representations for language that are useful for Demonstration video accompanying Learning Multi-Modal
Abstract: Zero-shot visual question answering (VQA) poses a formidable challenge at the intersection of computer vision and ... TerraMind, co-developed by IBM and ESA's Φ-lab, is the first generative,