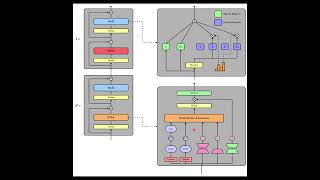
Media Summary: FLatten Transformer: Vision Transformer using Transformers are notoriously resource-intensive because their self- An overview of transforms, as used in LLMs, and the
Focused Linear Attention Explained In - Detailed Analysis & Overview
FLatten Transformer: Vision Transformer using Transformers are notoriously resource-intensive because their self- An overview of transforms, as used in LLMs, and the (e3v2) Ever wonder why neurodivergent (non- To try everything Brilliant has to offer—free—for a full 30 days, visit . You'll also get 20% off an annual ...