Media Summary: ... vs global minimum - Why this is the hyperparameter to tune If Cost functions and training for neural networks. Help fund future projects: Special thanks to ... Explore two learning algorithms for neural networks: stochastic
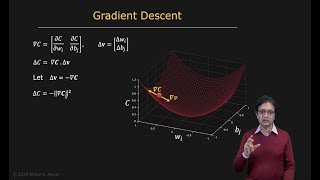
Finally Makes Sense Gradient Descent - Detailed Analysis & Overview
... vs global minimum - Why this is the hyperparameter to tune If Cost functions and training for neural networks. Help fund future projects: Special thanks to ... Explore two learning algorithms for neural networks: stochastic Try Brilliant Free for 30 Days + 20% Off Annual Premium Subscription: ➡️ Get Free ... First Principles of Computer Vision is a lecture series presented by Shree Nayar who is faculty in the Computer Science ... Visual and intuitive Overview of stochastic
Sebastian's books: Now that we understand function derivatives and