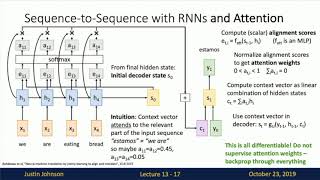
Media Summary: The source is a technical report introducing the Ring-linear model series, specifically the Ring-mini-linear-2.0 and ... An overview of transforms, as used in LLMs, and the FasterViT is a hybrid CNN-ViT neural network that combines the strengths of CNNs and ViTs, achieving high image throughput for ...
Efficient Length Generalizable Attention Via - Detailed Analysis & Overview
The source is a technical report introducing the Ring-linear model series, specifically the Ring-mini-linear-2.0 and ... An overview of transforms, as used in LLMs, and the FasterViT is a hybrid CNN-ViT neural network that combines the strengths of CNNs and ViTs, achieving high image throughput for ... In this AI Research Roundup episode, Alex discusses the paper: 'Rethinking the Role of Unlock the core technology behind modern AI language models in this deep dive into



![How Attention Got So Efficient [GQA/MLA/DSA]](https://i.ytimg.com/vi/Y-o545eYjXM/mqdefault.jpg)