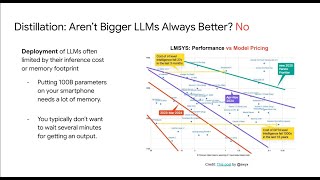
Media Summary: Jason Fries, a research scientist at Snorkel AI and Stanford University, discussed the challenges of deploying Large Language Models like GPT-4, DeepSeek, and Google Gemini or Flash comes with a major drawback—they are massive Foundation model performance at a fraction of the cost- model
Distilling Knowledge Into Tiny Llms - Detailed Analysis & Overview
Jason Fries, a research scientist at Snorkel AI and Stanford University, discussed the challenges of deploying Large Language Models like GPT-4, DeepSeek, and Google Gemini or Flash comes with a major drawback—they are massive Foundation model performance at a fraction of the cost- model This video lesson explores the power of Large Language Model








![How to Distill LLM? LLM Distilling [Explained] Step-by-Step using Python Hugging Face AutoTrain](https://i.ytimg.com/vi/tpMOF1cT4Fc/mqdefault.jpg)
![[Podcast] LLM Distillation: How to Shrink an AI](https://i.ytimg.com/vi/n_bgS2CeLhs/mqdefault.jpg)

