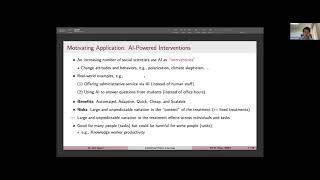
Media Summary: PRESENTERS Ahmad Beirami: Google DeepMind Hamed Hassani, University of Pennsylvania The second part of the tutorial ... Subscribe to the channel to get notified when we release a new video. Like the video to tell YouTube that you want more content ... PRESENTERS Ahmad Beirami: Google DeepMind Hamed Hassani, University of Pennsylvania In recent years, large language ...
Controllable Safety Alignment Inference Time - Detailed Analysis & Overview
PRESENTERS Ahmad Beirami: Google DeepMind Hamed Hassani, University of Pennsylvania The second part of the tutorial ... Subscribe to the channel to get notified when we release a new video. Like the video to tell YouTube that you want more content ... PRESENTERS Ahmad Beirami: Google DeepMind Hamed Hassani, University of Pennsylvania In recent years, large language ... At an Anthropic Research Salon event in San Francisco, four of our researchers—Alex Tamkin, Jan Leike, Amanda Askell and ... Knowing what actually causes the majority of serious injuries and fatalities is a good start, certainly much better than guessing or ... Writeup: Papers Is Best-of-N the Best of Them? Coverage, Scaling, and Optimality in ...
Today's ArXiv CS digest covers 10 hand-picked papers — starting with "When Autoregressive Consistency Hurts Fine-tuning your LLM on standard, benign domain data might be silently destroying its