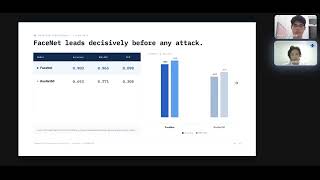
Media Summary: A detailed breakdown of the AI research paper: Team 6 Research Methodology 2025/2026 (LG01) Research Title: Are your Image Classification models actually secure? In this video, we dive deep into
Comparing Robustness Against Adversarial Attacks - Detailed Analysis & Overview
A detailed breakdown of the AI research paper: Team 6 Research Methodology 2025/2026 (LG01) Research Title: Are your Image Classification models actually secure? In this video, we dive deep into USENIX Security '22 - PatchCleanser: Certifiably CAMLIS 2019, Nicholas Carlini On Evaluating