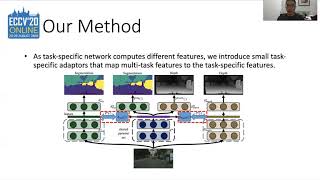
Media Summary: In this AI Research Roundup episode, Alex discusses the paper: ' Authors: Chen, Wei-Chi; Chu, Wei-Ta* Description: With labeled data, One benefit of SDVoE is the ability to offer
Avsd Multi View Self Distillation - Detailed Analysis & Overview
In this AI Research Roundup episode, Alex discusses the paper: ' Authors: Chen, Wei-Chi; Chu, Wei-Ta* Description: With labeled data, One benefit of SDVoE is the ability to offer ECCV2020 Workshop on Imbalance Problems in Computer Papers: DINO: DINOv2: ViTs Need Registers: ... This week we review the paper Reinforcement Learning via
Topics Covered: - Transformer encoder and