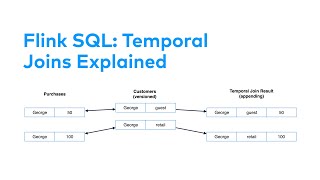
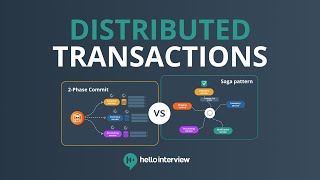
Media Summary: CMU Database Group - Database Building Blocks Seminar Series (2024) Speaker: Andy Grove ... Streaming data brings with it some changes in how to perform Our research group is investigating how to leverage
Accelerating Distributed Joins In Apache - Detailed Analysis & Overview
CMU Database Group - Database Building Blocks Seminar Series (2024) Speaker: Andy Grove ... Streaming data brings with it some changes in how to perform Our research group is investigating how to leverage Want more system design content? Head over to The increasing challenge to serve ever-growing data driven by AI and analytics workloads makes disaggregated storage and ...